| Python基础 | 您所在的位置:网站首页 › python zfill right › Python基础 |
Python基础
|
数据类型
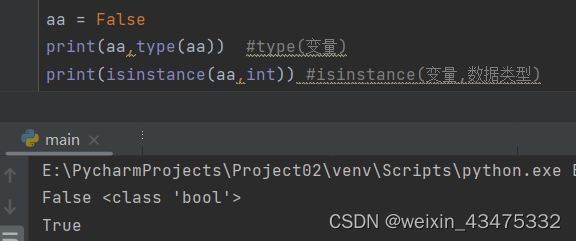
将一组具有相同性质的数据的集合统称为一种数据类型,在Pyhton中定义了很多种数据类型,每种数据类型以一个类(class)来定义,在类中定义每种数据类型的属性和方法。 我们可以使用内置函数type()来返回一个变量的数据类型,或者使用内置函数isinstance()来判断变量的数据类型,如下图
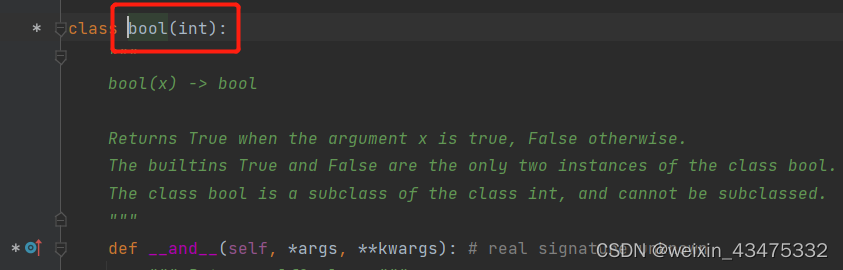
那这里为什么bool类型的变量,用isinstance()函数判断为int类型呢?我们按住ctrl键,点击int跳转到数据类型定义模块文件中,搜索bool类,可以看到bool类继承了int类,也就是说bool类是int类的子类,所以bool类型的数据也是int类型
几乎所有数据类型的对象都能进行真值测试,布尔运算和比较运算,这几个操作最终返回的都是布尔值,也就是返回真True或者假False 真值测试(逻辑值测试)任何对象都可以进行真值测试,一个对象在默认情况下被视为真值,除非当该对象被调用时其所属类定义了 __bool__方法且返回 False 或是定义了 __len__方法且返回零才会被视为假值。会被视为假值的内置对象如下: 被定义为假值的常量:None和False任何数值类型的0:0、0.0、0j、Decimal(0)、Fraction(0, 1)空的序列和多项集:‘’、[]、()、{}、set()、range(0)假设我们自定义了一个类,这个类的实例对象可以进行真值测试,那什么情况下这个对象进行真值测试会返回False呢? 第一种情况是在这个类中定义了__bool__方法且该方法return False,那么真值测试会返回False; 第二种情况是在这个类中定义了__len__方法且该方法return 0,那么真值测试会返回False。 如果一个类中即定义了__bool__方法,又定义了__len__方法,那么会先查看__bool__方法的返回值,如果返回值为False,那么直接是False,如果返回值是True,那么接着看__len__方法的返回值,返回值为0,那么就是False,返回值是非0,那么就是True 除上面两种情况之外,任何对象进行真值测试都默认返回True 布尔运算(and、or、not)任何对象在进行真值测试之后,都能作为布尔运算的操作数,布尔运算的运算规则如下: x and y:当x为假时,直接返回False;当x为真时,再对y求值,如果y为假则返回False,y为真则返回Truex or y:当x为真时,直接返回true;当x为假时,再对y求值,如果y为假则返回False,y为真则返回Truenot x:当x为真时,返回False;当x为假时,返回True 比较运算在Python中有八种比较运算符,他们的优先级相等(比布尔运算符的优先级高)。比较运算可以任意串联,比如:x'1':1,'2':2,'3':3} s = {'a','b','c','d'} print(','.join(a)) #s,d,g,h,,,e,r,b,j,p,n, ,v,q,h,i,f print(''.join(b)) #123abc print(','.join(c)) #1,2,3,a,b,c print(','.join(d)) #1,2,3 print(','.join(s)) #a,b,c,d str.partition(sep) 该方法可以将字符串转化为元组,始终返回三元元组,拆分规则如下: sep为空,那么抛出异常TypeErrorsep为空字符串,那么抛出异常ValueError如果sep在str中不存在,那么返回的元组中第一个元素为str,第二个和第三个元素为空字符串如果sep在str中存在,那么将第一个sep前面的字符作为返回元组的第一个元素,第二个元素为sep,sep后面的字符作为第三个元素 #partition()方法 a = 'sdghi,erbjpn vqhif' print(a.partition('123')) #('sdghi,erbjpn vqhif', '', '') print(a.partition('hi')) #('sdg', 'hi', ',erbjpn vqhif') str.split(sep=None, maxsplit=-1)该方法可以将字符串转化为列表,拆分规则如下: sep为空,那么默认分隔符为空格(多个空格也被看做一个空格),但是首尾的空格会被忽略sep为空字符串,抛出异常ValueErrorsep为普通字符串,但sep在str字符串中不存在,那么生成的列表仅包含str一个字符串sep为普通字符串,且sep在字符串中存在,那么会严格按照sep来分割str,将sep左右边的字符作为新列表的一个元素,如果str中存在几个连续的sep,那么会将这几个sep中间看作空字符存入新列表中如果指定了maxsplit,那么你将最多能够分割maxsplit次如果str是个空字符串,那么sep为空默认会返回一个空列表;sep不为空那么返回一个包含一个空字符串的列表 #字符串方法 a = ' 1323D VDWSdsvAsdvsaa a135fw ' print(a.split()) #['1323D', 'VDWSdsvAsdvsaa', 'a135fw'] #分隔符左右没字符的当作空字符来处理 print(a.split(' '*2)) #['', '1323D', '', '', '', '', 'VDWSdsvAsdvsaa', 'a135fw', ''] print(a.split('a')) #[' 1323D VDWSdsvAsdvs', '', ' ', '135fw '] print(a.split('3',2)) #[' 1', '2', 'D VDWSdsvAsdvsaa a135fw '] print(a.split('')) #ValueError: empty separator #str为空字符串 a = '' print(a.split('1')) #[''] print(a.split()) #[] #split()和rsplit()的区别 print(a.split('3',2)) #[' 1', '2', 'D VDWSdsvAsdvsaa a135fw '] print(a.rsplit('3',2)) #[' 132', 'D VDWSdsvAsdvsaa a1', '5fw '] str.splitlines(keepends=False)行边界符如下 表示符描述\n换行符\r回车符\r\n回车加换行\v或\x0b行制表符\f或\x0c换表单\x1c文件分隔符\x1d组分隔符\x1e记录分隔符\x85下一行\u2028行分隔符\u2029段分隔符 print('esgrh\nsd'.splitlines()) #['esgrh', 'sd'] print('esgrh\n'.splitlines()) #['esgrh'] print('\n'.splitlines()) #[''] print(''.splitlines()) #[] print(' ew'.splitlines()) #[' ew'] str.strip(chars)该方法用于移除字符串中前导和末尾的chars,移除规则如下: chars为空,那么默认移除str首尾的空格,如果str中只包含空格或者str是个空字符串,那么将返回一个空字符串chars为空字符串,那么直接返回strchars不为空,如果chars为单个字符,那么移除str中首尾的chars;如果chars为多个字符,那么移除首尾的chars,chars中的字符顺序不要求,比如str = ‘12abc’,那么想要移除abc,chars可以是’965abc’/‘acgfherb’/'c43ab’等带有abc三个字符的所有可能字符 #字符串方法 a = ' swesfrs' print(a.strip()) #swesfrs print(a.strip('')) # swesfrs #chars包含了末端字符'esfrs' print(a.strip('fevfas234r')) # sw #chars包含了'swesfrs',只要能在首端或末端将全部字符移除,那么另一个方向的空格符也会一同被移除 print(a.strip('wfevfas234r')) #空字符串 字符串格式化输出 f-string与{}表达式 在字符串前面加’f’或’F’前缀,那么就可以在字符串中使用{}表达式代表替换字段 name = 1.3141596 a = 12 b = 34 #两个花括号会被当作一个来对待 print(f"this is {{}},{{{a = }}},{b = }") #this is {},{a = 12},b = 34 # 替换字段后面加:,冒号后的第一位数代表该值的宽度 # 如果该值是个浮点数,那么宽度后面加小数点,小数点后面的数代表保留几位数(会进行四舍五入) # 如果小数点后面的数带一个f后缀,那就代表保留几位小数(会进行四舍五入) print(f'this is name={name:10.4f}') #this is name= 1.3142 # {}表达式输出计算结果 print(f'this is a+b={a+b}') #this is a+b=46 today = datetime(year=2023, month=3, day=5) #输出时间 print(today) print(f'{today=:%B %d %Y}') 占位符% 默认是以右对齐的方式输出,%-表示以左对齐的方式输出,%0表示输出宽度不够时用0填补,%+表示显示正数的正号,占位符如下 %c:格式化输出字符%d:格式化输出整数%u:格式化输出无符号整数%o:格式化输出无符号八进制数%x:格式化输出无符号十六进制数%f:格式化输出浮点数%s:格式化输出字符串 name = 'Python' c = 1.3141596 a = -12 b = 34 print('my name is %s' % name) print('(%d+%d)=%d' % (a,b,a+b)) print('this is %.4f' % c) print('%c' % name[0]) print('%u' % a) format()函数与{}表达式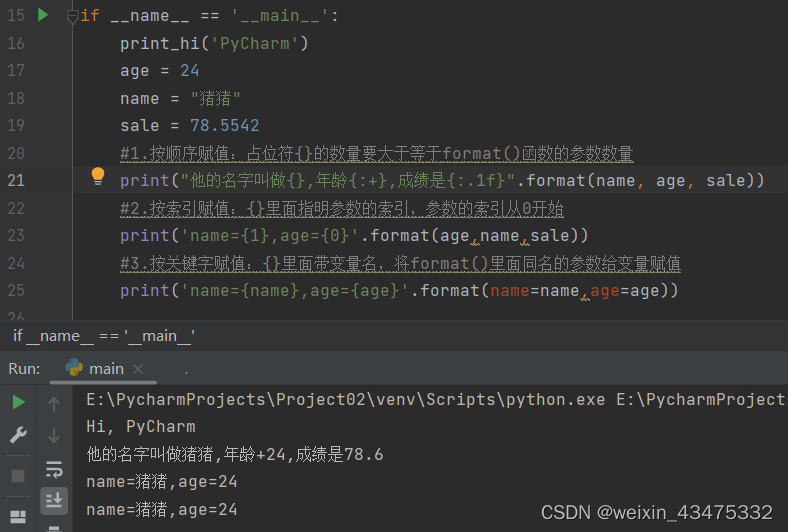 Tuple(元组)
定义元组 **当圆括号里面只有一个对象时,就表示该对象本身,而不是一个元组,如果想定义只包含一个元素的元组,那么元素后面必须有一个逗号
#定义元组
a = ()
print(a,type(a)) #()
#注意这样表示的是一个整数
b = (1)
print(b,type(b)) #1
#这样才表示的是只有一个元素的元组
b = (1,)
print(b,type(b)) #(1)
c = 1,
print(c,type(c)) #(1,)
d = 1,'2',3
print(d,type(d)) #(1, '2', 3)
e = (1,'2','12')
print(e,type(e)) #(1, '2', '12')
Tuple(元组)
定义元组 **当圆括号里面只有一个对象时,就表示该对象本身,而不是一个元组,如果想定义只包含一个元素的元组,那么元素后面必须有一个逗号
#定义元组
a = ()
print(a,type(a)) #()
#注意这样表示的是一个整数
b = (1)
print(b,type(b)) #1
#这样才表示的是只有一个元素的元组
b = (1,)
print(b,type(b)) #(1)
c = 1,
print(c,type(c)) #(1,)
d = 1,'2',3
print(d,type(d)) #(1, '2', 3)
e = (1,'2','12')
print(e,type(e)) #(1, '2', '12')
元组里面的元素可以是任何标准数据类型的对象 内置函数tuple() tuple()是Python的内置函数,用于生成一个空元组,或将可迭代对象转换成元组函数定义:class tuple(iterable) iterable–可迭代对象,可以是字符串、元组、列表、字典、集合等 a = tuple() print(a,type(a)) #() b = tuple('123abc,bca') print(b,type(b)) #('1', '2', '3', 'a', 'b', 'c', ',', 'b', 'c', 'a') c = tuple(('1',2,'3',)) print(c,type(c)) #('1', 2, '3') d = tuple([123,11,22,'a','b']) print(d,type(d)) #(123, 11, 22, 'a', 'b') e = tuple({1:'1',2:'2',3:'3'}) print(e,type(e)) #(1, 2, 3) f = tuple({11,22,'33'}) print(f,type(f)) #(11, '33', 22) List(列表) 定义列表 #定义列表 a = [] print(a,type(a)) #[] b = [a] print(b,type(b)) #[[]] c = [1,'2',(3,),[4],{5:5},{6}] print(c,type(c)) #[1, '2', (3,), [4], {5: 5}, {6}] #使用列表推导式[x for x in iterable] d1 = "zdfghnb" d = [x for x in d1] print(d,type(d)) #['z', 'd', 'f', 'g', 'h', 'n', 'b'] 内置函数list() list()是Python的内置函数,用来生成一个空列表,或将可迭代对象转化为列表类型函数定义:class list(iterable) iterable–可迭代对象,可以是字符串、元组、列表、字典、集合等 a = list() print(a,type(a)) #[] b = list('abcd') print(b,type(b)) #['a', 'b', 'c', 'd'] c = list((1,'2','abc')) print(c,type(c)) #[1, '2', 'abc'] d = list([11,22]) print(d,type(d)) #[11, 22] e = list({1:'1',2:'2',3:'3'}) print(e,type(e)) #[1, 2, 3] f = list({11,22,'33'}) print(f,type(f)) #['33', 11, 22] 列表方法列表对象的所有方法如下 list.append(x)该方法用于在列表末尾追加一个元素,参数不能为空,x可以是任何数据类型 #列表方法list.append() a = [] a.append(1) a.append(False) a.append('') a.append(()) a.append([]) a.append({}) a.append({1}) print(a) #[1, False, '', (), [], {}, {1}] list.extend(iterable)该方法用于在列表末尾追加一个可迭代对象,将可迭代对象中的每一项作为一个元素追加到列表中,当参数为字典时追加的是他的key #列表方法list.aextend() a = [] a.extend('123') a.extend(('123','123',(11,22))) a.extend(['1','2','12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) print(a) #['1', '2', '3', '123', '123', (11, 22), '1', '2', '12', 1, 2, 3, 'c', (12, 23), 'a', 'b'] list.insert(i,x)该方法用于在列表的指定位置i插入元素x,i代表插入元素的索引,x可以是任何数据类型 i可以是负数,0,正数:当i为正数或0时,元素插入之后的索引就是i;当i为负数时,元素插入之后的索引就是i-1;当i大于等于列表长度时,就在末尾插入元素 #列表方法list.insert() a = [] a.extend('123') a.extend(('123','123',(11,22))) a.extend(['1','2','12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) print(a) #[True, '1', '2', '3', '123', '123', (11, 22), -1, '1', '2', '12', 1, 2, 3, 'c', (12, 23), 'b', 'a'] list.remove(x)该方法用于从列表中删除第一个值为x的元素,元素未找到就抛出异常ValueError 删除时会把True看作1,False看作0 #列表方法list.remove() a = [] a.extend('123') a.extend(('123','123',(11,22))) a.extend(['1',0,'12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) a.insert(len(a)+5,0) print(a) #[True, '1', '2', '3', '123', '123', (11, 22), -1, '1', 0, '12', 1, 2, 3, 'a', (12, 23), 'c', 'b', 0] a.remove('123') a.remove(False) print(a) #[True, '1', '2', '3', '123', (11, 22), -1, '1', '12', 1, 2, 3, 'a', (12, 23), 'c', 'b', 0] list.pop([i])该方法用于从列表中删除指定位置的元素,并返回该元素。i代表需要删除的元素的下标,这个下标必须存在,如果不存在抛出异常IndexError;i可以不写,当参数为空时默认删除最后一个元素 #列表方法list.pop() a = [] a.extend('123') a.extend(('123','123',(11,22))) a.extend(['1','2','12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) a.insert(len(a)+5,-5) a.remove('123') print(a.pop()) #-5 print(a.pop(-10)) #1 print(a) #[True, '1', '2', '3', '123', (11, 22), -1, '2', '12', 1, 2, 3, 'c', 'a', (12, 23), 'b'] list.clear()该方法用于清空列表元素 #列表方法list.clear() a = [] a.extend('123') a.extend(('123','123',(11,22))) a.extend(['1','2','12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) a.insert(len(a)+5,-5) a.remove('123') print(a.pop()) #-5 print(a.pop(-10)) #1 a.clear() print(a) #[] list.index(x[, start[, end]])该方法用于返回列表中第一个值为x的索引,找不到就抛出异常ValueError。可选参数start和end用于限定查找范围,两个参数的值都代表的下标 index方法总是从左向右查找的start和end可以是正数、0、负数:start不一定要比end数值大,但start代表的下标值一定要在end的左边,否则直接抛出异常ValueError找的时候True会看作1,False会看作0 #列表方法list.index() a = [] a.extend('123') a.extend(('123','123',(11,22))) a.extend(['1',0,'12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) a.insert(len(a)+5,0) print(a.index(1)) #0 print(a.index(False)) #9 print(a.index('1',5,-5)) #8 print(a) #[True, '1', '2', '3', '123', '123', (11, 22), -1, '1', 0, '12', 1, 2, 3, 'c', (12, 23), 'b', 'a', 0] list.count(x)该方法用于返回列表中元素x出现的次数,同样的会把True看作1,False看作0 #列表方法list.count() a = [] a.extend('123') a.extend(('123','123',())) a.extend(['1',0,'12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) a.insert(len(a)+5,0) print(a.count(1)) print(a.count(False)) print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0] list.sort()该方法详看下面排序介绍 list.reverse()该方法用于反转列表元素,顺序颠倒 #列表方法list.reverse() a = [] a.extend('123') a.extend(('123','123',())) a.extend(['1',0,'12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) a.insert(len(a)+5,0) print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0] a.reverse() print(a) #[0, 'c', 'b', 'a', (12, 23), 3, 2, 1, '12', 0, '1', -1, (), '123', '123', '3', '2', '1', True] list.copy()该方法用于返回列表的浅拷贝,拷贝跟赋值很像,但也有区别。如果是赋值,那么两个变量指向的是同一个对象,相当于两个变量指向的是同一个地址空间,而拷贝有时候并不是这样。浅拷贝的规则如下: 如果要拷贝的变量是一个不可变类型,那么经过浅拷贝之后得到的变量将和原变量指向同一个地址,两个变量绑定同一个对象如果要拷贝的变量是一个可变类型,那么经过浅拷贝之后得到的变量的地址和原变量地址不相同,相当于新创建了一个对象,两个变量绑定了不同对象,只是对象值相等如果要拷贝的是一个复合类型(也就是不可变类型里面有可变类型的元素,如元组里面包含列表元素,或者可变类型里面有不可变类型元素,如列表里面包含整型等),首先浅拷贝会看最外层的是什么类型,也就是看这个变量是什么类型,如果是不可变类型,那么浅拷贝之后得到的变量的地址和原变量相同;如果是可变类型,那么浅拷贝之后得到的变量的地址和原变量地址不相同;但无论外层是什么类型对于里面的元素来说,浅拷贝之后的元素和原来的元素地址都是相同的 #list.copy() a = [1,'2',(3,4),[5,6],{7:7},{8}] b = a.copy() print(b) print(id(a)) #2783887325120 print(id(b)) #2783891229632 print(a[0] is b[0]) #True print(a[1] is b[1]) #True print(a[2] is b[2]) #True print(a[3] is b[3]) #True print(a[4] is b[4]) #True print(a[5] is b[5]) #True还可以使用copy模块来进行浅拷贝和深拷贝,使用之前需要import copy,浅拷贝方法是copy.copy(x),深拷贝方法是copy.deepcopy(x) 深拷贝规则对于不是复合类型的变量来说跟浅拷贝一样,类型不可变,拷贝之后地址相同,类型可变拷贝之后地址不相同。而对于复合类型来说深拷贝和浅拷贝有所不同,浅拷贝是内层元素地址均不变,外层可变地址就不同,不可变地址就相同,但深拷贝是根据内层元素类型来决定外层拷贝后地址是否相同的。具体就是:如果内层包含可变类型,那么不管外层是什么类型,深拷贝之后得到的变量地址和原变量不相同,里面的元素是可变类型的地址就不相同,是不可变类型的地址就相同;如果内层不包含可变类型,那么再看外层,如果外层是不可变类型那么深拷贝之后得到的变量地址和原变量相同,如果外层是可变类型,那么深拷贝之后得到的变量地址和原变量不相同,里面的元素因为都是不可变类型的,所以深拷贝之后地址都相同 import copy a = (1,'2',(3,4),[5,6],{7:7},{8}) b = copy.deepcopy(a) print(b) print(id(a)) #2452158272832 print(id(b)) #2452158276576 print(a[0] is b[0]) #True print(a[1] is b[1]) #True print(a[2] is b[2]) #True print(a[3] is b[3]) #False print(a[4] is b[4]) #False print(a[5] is b[5]) #False import copy a = (1,'2',(3,4)) b = copy.deepcopy(a) print(b) print(id(a)) #1635445769408 print(id(b)) #1635445769408 print(a[0] is b[0]) #True print(a[1] is b[1]) #True print(a[2] is b[2]) #True del语句del语句可以按索引删除列表中的值,也可以命名空间中直接删除列表变量 #del语句 a = [] a.extend('123') a.extend(('123','123',())) a.extend(['1',0,'12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) a.insert(len(a)+5,0) print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0] del a[0] del a[0:5] print(a) #[(), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0] del a print(a) #NameError: name 'a' is not defined 列表排序 简单排序 list.sort() list.sort()方法是列表的内置方法,用于直接修改列表进行排序,由于是在各项间进行比较来排序的,所以如果比较操作失败,整个排序失败,就会导致这个列表处在被部分修改的状态方法定义:list.sort(*, key=None, reverse=False) 该方法接收两个仅限关键字形式传入的参数,*后面定义的便是仅限关键字形参key=None:这个参数只能是带有一个参数的函数,该函数用来从每个列表元素中提取比较键,sort()将使用这个键值进行排序。key为空会直接比较元素进行排序,而不用计算一个单独的键值reverse=False:这个参数用于指明排序的方向,False代表正向排序,True代表反向排序 #list.sort()排序 a = [4,6,8,3,0,5,1] a.sort() print(a) #[0, 1, 3, 4, 5, 6, 8] a.sort(reverse=True) print(a) #[8, 6, 5, 4, 3, 1, 0] b = ['a','s','D','f','g','h'] #sort()默认是比较ASCII码大小来排序的 b.sort() print(b) #['D', 'a', 'f', 'g', 'h', 's'] #str.lower用于在比较前将每一项全部转换为小写 b.sort(key=str.lower) print(b) #['a', 'D', 'f', 'g', 'h', 's'] 内置函数sorted() sorted()是Python的内置函数,用于给可迭代对象进行排序并返回一个已排序列表,所以他所服务的对象不仅仅是列表,而且他和list.sort()最大的区别在于他不会去直接修改原对象,而是对原对象排序后返回一个新的已排序列表函数定义:sorted(iterable, /, *, key=None, reverse=False) 该方法的第一个参数iterable是个仅限位置形式传入的参数,他后面使用/来定义了,而*后面的是两个仅限关键字形式传入的参数iterable:可迭代对象key=None:这个参数只能是带有一个参数的函数,该函数用来从iterable的每个元素中提取比较键,sorted()将使用这个键值进行排序。key为空会直接比较元素进行排序,而不用计算一个单独的键值reverse=False:这个参数用于指明排序的方向,False代表正向排序,True代表反向排序 #sorted()排序 #将字符串排序 a = 'asdfgnbvc' print(sorted(a)) #将元组排序 b = ('ad','wgvd','dQ','SA') print(sorted(b)) #将列表排序 c = [3,45,67,32,76] print(sorted(c)) #将字典排序,只对key排序输出 d = {'1':1,'9':2,'3':0} print(sorted(d)) #对集合排序 e = {11,4,9,3,-1} print(sorted(e)) 高级排序list.sort() 和 sorted() 都有一个 key 形参用来指定在进行比较前要在每个列表元素上调用的函数(或其他可调用对象),下面我们来指定关键函数进行排序 #使用str.lower函数 a = "This is a test string from Andrew".split() a.sort(key=str.lower) #['a', 'Andrew', 'from', 'is', 'string', 'test', 'This'] print(a) b = sorted("This is a test string from Andrew".split(),key=str.lower) print(b) #使用lambda函数 ss = [('shanghai',80),('guangzhou',90),('hangzhou',70)] ssa = sorted(ss,key=lambda x:x[1]) print(ssa) #[('hangzhou', 70), ('shanghai', 80), ('guangzhou', 90)] ss.sort(key=lambda x:x[0]) print(ss) #[('guangzhou', 90), ('hangzhou', 70), ('shanghai', 80)] 列表去重 set()去重利用集合元素的不重复性,可以使用set()将列表转换为一个集合,然后再将集合使用list()转换为列表,达到去重的目的 #set()去重 a = [] a.extend('123') a.extend(('123','123',())) a.extend(['1',0,'12']) a.extend({1:[1],2:[2],3:[3]}) a.extend({'a','b','c',(12,23)}) a.insert(0,True) a.insert(-10,-1) a.insert(len(a)+5,0) print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0] a = list(set(a)) print(a) #[0, True, '123', 2, '2', '1', '3', 3, (12, 23), 'a', '12', 'b', (), 'c', -1]但利用set()去重之后原列表的顺序就改变了,如果想要保持原列表的顺序那么可以结合sorted()方法一起使用 print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0] b = list(set(a)) print(b) #[0, True, '123', 2, '2', '1', '3', 3, (12, 23), 'a', '12', 'b', (), 'c', -1] b.sort(key=a.index) print(b) #[True, '1', '2', '3', '123', (), -1, 0, '12', 2, 3, 'b', (12, 23), 'c', 'a'] #使用sorted()更便捷,一行代码搞定 a = sorted(list(set(a)),key=a.index) print(a) #[True, '1', '2', '3', '123', (), -1, 0, '12', 2, 3, 'b', 'c', (12, 23), 'a'] dict.fromkeys()去重利用字典键key的不重复性将列表中的项作为字典的键创建一个字典,然后再使用list()将字典转换为列表,达到去重的目的,这种方式还可以保留列表的原序 dict.fromkeys(iterable[,x])方法用于创建一个新字典,该字典的键来源于可迭代对象里面的每一项元素,而键值默认都是None,我们也可以指定每项的初始化键值x #dict.fromkeys()去重 a = [True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0] b = list(dict.fromkeys(a)) print(b) #[True, '1', '2', '3', '123', (), -1, 0, '12', 2, 3, (12, 23), 'a', 'c', 'b'] range对象range 类型表示不可变的数字序列,通常用于在 for 循环中指定循环的次数 类型定义:class range(start, stop[, step]) 参数必须是整数,或者任何实现了__index__()方法的对象必须带有stop参数,否则引发TypeError,range(0)返回空start和step参数可以省略,省略时start默认为0,step默认为1如果 step 为零,则会引发 ValueError如果step为正数,那么start必须小于stop,否则返回空。range(start,stop,step)表示从start开始取值,然后每隔step取一个值,取到stop-1为止如果step为负数,那么start必须大于stop,否则返回空。range(startstop,step)表示从start开始取值,然后每隔step取一个值,取到stop-1为止 a = str(range(5,2)) print(a) #range(5, 2) t = tuple(range(10)) print(t) #(0, 1, 2, 3, 4, 5, 6, 7, 8, 9) s = list(range(1,20,3)) print(s) #[1, 4, 7, 10, 13, 16, 19] s1 = list(range(0)) print(s1) #[] s2 = list(range(10,20,-2)) print(s2) #[] d = set(range(10,2,-1)) print(d) #{3, 4, 5, 6, 7, 8, 9, 10} 映射类型目前只有一种标准的映射类型,那就是字典。字典的键可以是任何可哈希对象,但键具有唯一性,所以当数字类型作为键时,如果两个数在字面上相等,比如1和1.0,那么当将这两个数都作为键时,字典中只会创建一个映射,而这两个数都可以被用来索引同一个条目 Dict(字典) 定义字典 #定义字典 a = 1 b = '12' c = (23,'3') #由于1和1.0在字面上相等,所以只会创建一个映射,键值取后写的那个 d = {a:10,b:2,c:3,1.0:4} print(d) #{1: 4, '12': 2, (23, '3'): 3} #任何值为1的键都可以用来索引同一条目 print(d[1],d[1.0],d[True]) #4 4 4 d1 = {} print(d1) #{} #使用字典推导式 d2 = {x:x for x in range(4)} print(d2) #{0: 0, 1: 1, 2: 2, 3: 3} 内置函数dict() dict()是Python内置的字典构造器,用于生成一个空字典或将其他类型转换为字典函数定义:class dict(**kwargs)或class dict(mapping,**kwargs)或class dict(iterable,**kwargs) 如果参数为空,则创建一个空字典如果参数是一个mapping对象(字典),那么将返回一个与该对象键值对相同的新字典如果参数为可迭代对象(元组、列表),那么该可迭代对象中的每一项必须刚好包含两个元素,每一项的第一个元素会作为字典的键,所以只能是可哈希对象,第二个元素会作为字典的键值,所以可以是任何对象。可迭代对象中有多少项就会创建多少个键值对,当然键重复的项只会创建一个映射,该映射的键值将会是最后一个元素对象如果给出关键字参数,关键字参数必须在位置参数后面,这个关键字会直接作为字典的键,关键字的值作为该键的键值,如果要加入的键已存在,来自关键字参数的值将替代来自位置参数的值 #dict() d1 = {1:'a',2:'b','3':'c'} d2 = dict(d1) print(d2) #{1: 'a', 2: 'b', '3': 'c'} print(d2 is d1) #False d2 = dict(((1,2),)) print(d2) #{1: 2} d3 = dict([(1,['a']),[2,'b'],('one','abc')],one=123) print(d3) #{1: ['a'], 2: 'b', 'one': 123} d4 = dict(one='aa',two='bb',three='cc') print(d4) #{'one': 'aa', 'two': 'bb', 'three': 'cc'} d5 = dict(zip('iloveyou',(0,1,3,[5]))) print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5]} 字典方法 len(d)返回字典d中的项数 d[key]返回字典d中以key为键的键值,如果key不存在将引发KeyError异常 d[key]=value将字典d中以key为键的项的键值设为value,如果key存在那么相当于修改键值,如果key不存在那么相当于添加新的项 del d[key]将字典d中以key为键的项移除,如果d[key]不存在将引发KeyError异常 if key in d如果键key在字典d中,那么返回True,否则返回False if key not in d如果键key不在字典d中,那么返回True,否则返回False iter(d)返回以字典d中的键为元素的迭代器 d.clear()清空字典d d.copy()返回字典d的浅拷贝 dict.fromkeys(iterable[,value])使用该方法来创建一个新字典,新字典的键来自可迭代对象,所以可迭代对象参数中不能有不可哈希的项,否则将引发TypeError异常,可以指定每个键的默认键值,如果不指定那么默认为None d.get(key[,default])从字典d中获取键为key的键值,如果key不在d中就返回default,default默认为None d.items()返回字典d的每一项(键:键值)组成的一个新视图,可以用来循环遍历字典 d.keys()返回字典d的每个键组成的一个新视图,可以用来循环遍历字典的键 d.values()返回字典d的每个键值组成的一个新视图,可以用来循环遍历字典的键值 d.pop(key[,default])移除字典d中键为key的项,并返回key的键值,如果key不存在则不会执行移除动作,直接返回default,如果default没有定义那么将引发KeyError异常 d.popitem()移除字典d的最后一项,并返回最后的一项(键:键值),如果字典为空将引发KeyError异常 reversed(d)返回一个逆序获取字典d中的键的迭代器,这个迭代器既然是逆序取字典的键,那么就可以用该迭代器生成一个元组或列表 a = [11,22,33] b = dict.fromkeys(a,'ab') print(b) #{11: 'ab', 22: 'ab', 33: 'ab'} print(list(reversed(b))) #[33, 22, 11] d.setdefault(key[,default])如果字典d中存在key,那么返回key的键值,否则将key加入字典d中,key的键值就是default,并返回default,如果default未指定,那么默认为None d.update([other])使用来自other的键值对更新字典d,如果键存在了就覆盖,该方法会返回None。参数为空时什么都不做,仍然返回None;参数为字典对象时,将该字典对象的键值对追加到字典d的末尾;参数可以是任何空的可迭代对象,什么都不做,仍然返回None;参数还可以是关键字参数;参数还可以是元组或列表或集合,但要求这些参数对象中只能包含键值对,也就是这些参数对象中的每一项只能是只包含两个对象的元组或列表,且第一个对象只能是可哈希的,会将每一项的第一个对象作为字典d的键,第二个元素作为字典d的键值追加到字典d中,看下面的实例更清晰 d5 = dict(zip('iloveyou',(0,1,3,[5]))) print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5]} #参数为字典 other = {'i':333,'sb':'sbsbsb'} print(d5.update(other)) #None print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb'} #参数为空 other = '' print(d5.update(other)) #None print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb'} #参数为元组 other = ((21,22),['fd','gf'],['kkk',[1,2,3]]) print(d5.update(other)) #None print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb', 21: 22, 'fd': 'gf', 'kkk': [1, 2, 3]} #参数为列表 other = [(21,20),['fd','df'],['kkk',[1,2,3]]] print(d5.update(other)) #None print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb', 21: 20, 'fd': 'df', 'kkk': [1, 2, 3]} #参数为集合,集合里面不能出现任何不可哈希对象 other = {(21,(25,False)),(9,0)} print(d5.update(other)) #None print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb', 21: (25, False), 'fd': 'df', 'kkk': [1, 2, 3], 9: 0} #参数为关键字参数 other = {'i':333,'sb':'sbsbsb'} d5.update(one='one',two='two') print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5], 'one': 'one', 'two': 'two'} d | other合并两个字典并返回一个新的字典,d和other都必须是字典,如果两者中存在相同的键,那么以other的值作为键值 d5 = dict(zip('iloveyou',(0,1,3,[5]))) print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5]} #d | other other = {'i':333,'sb':'sbsbsb'} print(other | d5) #{'i': 0, 'sb': 'sbsbsb', 'l': 1, 'o': 3, 'v': [5]} d |= other用other的键值对更新d,相当于d.update(other) 字典的比较运算字典只能进行等于(==)或不等于(!=)比较,无法进行(‘>’,‘=’,‘1,2,3,4} print(a,type(a)) #{1, 2, 3, 4} b = {'1','2','3'} print(b,type(b)) #{'3', '2', '1'} c = {(1,),(2,)} print(c,type(c)) #{(1,), (2,)} #注意这里定义的是空字典,而不是空集合,空集合只能使用集合函数来创建 d = {} print(d,type(d)) #{} #使用集合推导式 e = {x for x in '123456789'} #{'4', '8', '9', '3', '2', '7', '1', '5', '6'} print(e,type(e)) dd = {[1],[2]} print(dd,type(dd)) #TypeError: unhashable type: 'list' 内置函数set()和frozenset() set()函数和frozenset()函数都是集合的构造器,区别在于frozense()创建的是一个不可变的集合,是可哈希的,而set()函数创建的是可变的集合,不可哈希,所以frozense()创建的集合可以当作字典的键或者集合元素 函数定义:class set([iterable])或class frozenset([iterable]) 参数为空时,生成一个空集合参数是可迭代对象,但可迭代对象里面不能有不可哈希的元素 #set()和frozenset() a = frozenset() b = set() print(hash(a)) #133146708735736 print(hash(b)) #TypeError: unhashable type: 'set' #参数为空 a = frozenset() b = set() print(a,b) #frozenset() set() #参数是字符串 a = frozenset('abc') b = set('12345') print(a,b) #frozenset({'a', 'c', 'b'}) {'3', '1', '2', '5', '4'} #参数是元组,元组里面不能包含不可哈希对象 a = frozenset((1,2,'a','b')) b = set(('a1','a2','a3')) print(a,b) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} #参数是列表,列表里面不能包含不可哈希对象 a = frozenset([1,2,'a','b']) b = set(['a1','a2','a3']) print(a,b) #frozenset({1, 2, 'a', 'b'}) {'a2', 'a3', 'a1'} #参数是字典,取字典的key a = frozenset({1:1,2:'a',3:3}) b = set({1:1,2:'a',3:3}) print(a,b) #frozenset({1, 2, 3}) {1, 2, 3} #参数是frozenset对象 b = set(a) print(b) #{1, 2, 'a', 'b'} 集合方法 len(s)返回集合s的元素数量 if x in s如果x在集合s中存在,那么返回True,否则返回False if x not in s如果x不在集合s中,那么返回True,否则返回False s.isdisjoint(other)如果集合s中没有与集合other共有的元素,那么返回True,否则返回false,也就是用来判断两个集合是否有交集,有返回False,没有返回True s.issubset(other)用于判断集合s是否是集合other的子集,如果是返回True,否则返回False。相关运算有s < other和s other和s >= other s.union(*others)返回集合s以及other指定的集合中的所有元素组成的一个新集合。计算集合的并集,相关运算有set | other |… s.intersection(*others)返回集合s以及other指定的集合中的公有元素组成的一个新集合。计算集合的交集,相关运算有set & other & … s.difference(*others)返回集合s中有的,但other指定集合中没有的元素组成的一个新集合。计算集合的差集,相关运算有set - other - … s.symmetric_difference(other)返回集合s中有的但集合other中没有的,或集合other中有的但集合s中没有的元素组成的一个新集合。计算集合的补集,相关运算有set ^ other s.copy()返回集合s的浅拷贝 上面几个函数的other参数不要求一定是集合,也可以是可迭代对象 set方法由于set实例可变而frozenset实例不可变,所以下面是set对象独有的方法 s.update(*others)更新集合s,添加来自 others 中的所有元素,该方法返回None,相当于s |= other |= …运算 s.intersection_update(*others)更新集合s,只保留在所有other中也存在的元素,该方法返回None,相当于s &= other &=…运算 s.difference_update(*others)更新集合s,移除也存在于所有other中的元素,该方法返回None,相当于s -= other -=…运算 s.symmetric_difference_update(other)更新集合s,只保留存在于集合的一方而非共同存在的元素,该方法返回None,相当于s ^= other s.add(elem)将元素elem添加到集合s中,该方法返回None s.remove(elem)移除集合s中的elem元素,如果elem不存在集合s中将引发KeyError异常 s.discard(elem)如果元素elem存在集合s中就将它移除,否则什么也不做,该方法返回None s.pop()从集合中移除任意一个元素,并返回该元素的值。如果集合为空将引发keyError异常 s.clear()清空集合s中的元素,该方法返回None 集合运算求两个集合的并集、交集、差集、补集,set对象和frozenset对象运算的结果会是一个frozenset对象 并集set_a | set_b a = frozenset((1,2,'a','b')) b = set((1,'a1','a2','a3')) c = set('1njq') print(a,b,c) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} {'q', 'n', '1', 'j'} print(a | b) #frozenset({'a2', 1, 2, 'a', 'a1', 'b', 'a3'}) print(b | c) #{1, 'q', '1', 'a2', 'j', 'n', 'a1', 'a3'} 交集set_a & set_b a = frozenset((1,2,'a','b')) b = set((1,'a1','a2','a3')) c = set('1njq') print(a,b,c) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} {'q', 'n', '1', 'j'} print(a & b) #frozenset({1}) print(b & c) #set() 差集set_a - set_b a = frozenset((1,2,'a','b')) b = set((1,'a1','a2','a3')) c = set('1njq') print(a,b,c) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} {'q', 'n', '1', 'j'} print(a - b) #frozenset({2, 'a', 'b'}) print(b - c) #{'a1', 'a2', 'a3', 1} 补集set_a ^ set_b a = frozenset((1,2,'a','b')) b = set((1,'a1','a2','a3')) c = set('1njq') print(a,b,c) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} {'q', 'n', '1', 'j'} print(a ^ b) #frozenset({2, 'a1', 'a3', 'a2', 'b', 'a'}) print(b ^ c) #{'q', 1, 'a1', 'n', 'a3', 'a2', 'j', '1'}参考资源: https://docs.python.org/zh-cn/3.9/library/stdtypes.html# |
【本文地址】